内容:
a. DeepSeek-671B 大模型部署于两台配备 8卡 L20 GPU 的服务器。技术栈采用 Docker 容器化技术,VLLM高性能推理引擎和 Ray 分布式计算框架。
b. 官方文档: VLLM-Distributed
c. 官方教程操作流程繁琐,需要在多个SSH会话窗口之间频繁切换。为简化部署过程,本文基于官方文档进行了流程整合与优化,将原本分散的步骤系统化整理,提供一套更为简洁明了的一站式部署指南。
前置条件:
a. 两台服务器上安装:Docker,Nvidia驱动,Nvidia container toolkit。
b. 确认两台服务器网络硬件配置(可与硬件厂商确认)。可使用 ifconfig 和 ping 来确认网络连接。
c. 下载 DeepSeek-671B模型+ VLLM的docker镜像至两台服务器上。本示例使用DeepSeek-V3(int4 版本)。
确认服务器的网络配置并在下方docker compose 文件里调整环境变量:
#IB网络确认:
ibv_devinfo
显示No IB devices found 指无IB网络设备,
显示Link layer: Ethernet则网卡是RoCE而非IB,
显示Link layer: InfiniBand则是IB网络
#如果因为服务器无IB设备或者IB设备不一致而需要禁用IB网络:
NCCL_IB_DISABLE=1 --禁用IB
NCCL_IBEXT_DISABLE=1 --禁用RoCE
#如果有ib网络则可配置如下,自行调整网卡名称:
- NCCL_SOCKET_IFNAME=bond0
- GLOO_SOCKET_IFNAME=bond0
- NCCL_IB_HCA=mlx5_0,mlx5_3
- NCCL_IB_TIMEOUT=22
- NCCL_IB_DISABLE=0
- NCCL_DEBUG=INFO
#如果无ib网络则可配置如下,自行调整网卡名称:
- GLOO_SOCKET_IFNAME=bond0
- NCCL_SOCKET_IFNAME=bond0
- NCCL_IB_DISABLE=1
- NCCL_IBEXT_DISABLE=1
- NCCL_DEBUG=INFO
Ray框架需要确认头节点(head node)和子节点(worker node)。两台服务器上分别准备docker compose 文件:
#定义变量:
# 头节点:
VLLM_HOST_IP --本机ip
RAY_PORT --本机ray端口号,和模型服务使用端口号有所区分
VOLUME_DS_RAY --本机RAY日志存储位置(可选)
VOLUME_DS_V3_MODEL_PATH --本机模型路径
# 子节点:
VLLM_HOST_IP --本机ip
RAY_HEAD_IP --头节点的ip,与上面的VLLM_HOST_IP保持一致
RAY_PORT --头节点使用的IP,与上面的RAY_PORT保持一致
VOLUME_DS_RAY --本机RAY日志存储位置(可选)
VOLUME_DS_V3_MODEL_PATH --本机模型路径
#头节点部分
node-head-ds-v3:
image: vllm/vllm-openai:v0.11.0
container_name: node-head-ds-v3
entrypoint: ["/bin/bash", "-c", "ray start --block --head --node-ip-address=${VLLM_HOST_IP} --port=${RAY_PORT}"]
network_mode: host
privileged: true
shm_size: 64g
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ['0', '1', '2', '3', '4', '5', '6', '7']
volumes:
- ${VOLUME_DS_V3_PATH}:/ds-v3
- ${VOLUME_DS_V3_PATH}/ray:/tmp/ray
- ${VOLUME_DS_V3_MODEL_PATH}:/models
environment:
- NCCL_IB_HCA=mlx5_0,mlx5_3
- NCCL_SOCKET_IFNAME=bond0
- GLOO_SOCKET_IFNAME=bond0
- NCCL_DEBUG=INFO
- VLLM_HOST_IP=${VLLM_HOST_IP}
- NCCL_IB_TIMEOUT=22
- NCCL_IB_DISABLE=0
#子节点部分
node-worker-ds-v3:
image: vllm/vllm-openai:v0.11.0
container_name: node-worker-ds-v3
entrypoint: ["/bin/bash", "-c", "ray start --block --address=${RAY_HEAD_IP}:${RAY_PORT}"]
network_mode: host
privileged: true
shm_size: 64g
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ['0', '1', '2', '3', '4', '5', '6', '7']
volumes:
- ${VOLUME_DS_V3_PATH}:/ds-v3
- ${VOLUME_DS_RAY}/ray:/ds-v3/tmp/ray
- ${VOLUME_DS_V3_MODEL_PATH}:/models
environment:
- GLOO_SOCKET_IFNAME=bond0
- NCCL_SOCKET_IFNAME=bond0
- VLLM_HOST_IP=${VLLM_HOST_IP}
- NCCL_IB_HCA=mlx5_0,mlx5_3
- NCCL_IB_TIMEOUT=22
- NCCL_IB_DISABLE=0
两个节点分别启动容器,然后进入头节点容器,确认ray框架搭建成功,即可启动服务
--头节点
docker compose up -d node-head-ds-v3
--子节点
docker compose up -d node-worker-ds-v3
--进入头节点:
sudo docker exec -it node-head-ds-v3 bash
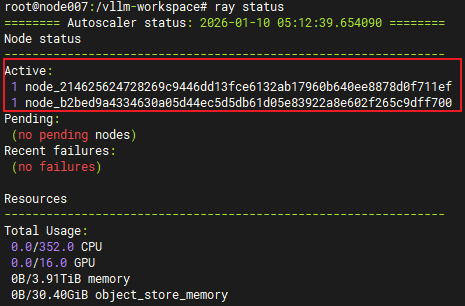
--查看ray节点连接情况:
ray status
--RAY框架需要头节点和子节点互通,本次实践中在子节点使用以下命令打开防火墙限制(可选):
sudo ufw allow from $VLLM_POST_IP
--出现两个 Active Node即连接成功
--启动vllm服务(可自行调整参数):
vllm serve /models --host 0.0.0.0 --port 20000 --trust-remote-code --served-model-name deepseek-671b-v3 --gpu-memory-utilization 0.8 --max-model-len 65536 --tensor-parallel-size 8 --pipeline-parallel-size 2 --enable-chunked-prefill --max_num_batched_tokens 2048
--如果打印日志中出现以下内容,则说明服务使用ib网络。
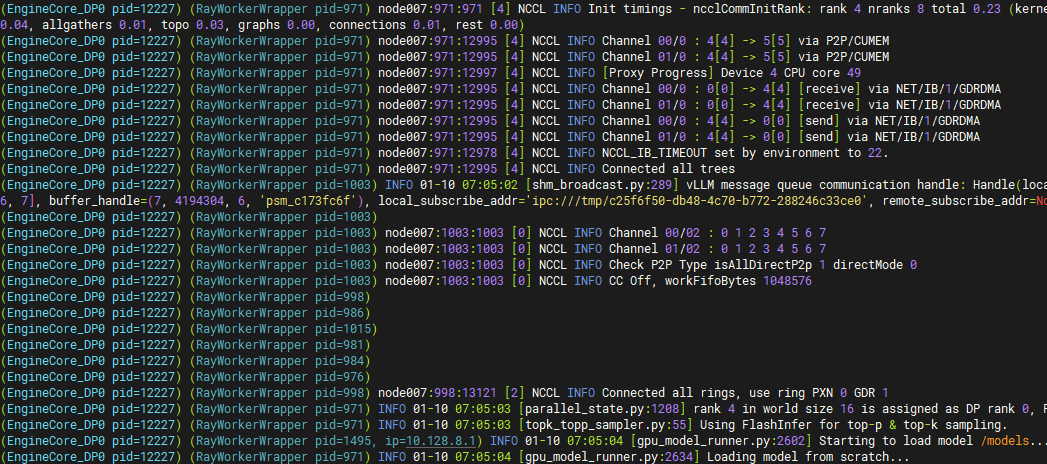
验证是否启动成功并查看吞吐量:
curl http://{your-ip}}:{your-port}/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-671b-v3",
"messages": [
{"role": "system", "content": "你是一个严谨的技术助手"},
{"role": "user", "content": "详细的解释什么是达梦,并给出安装步骤"}
],
"temperature": 0.7,
"max_tokens": 2048
}'

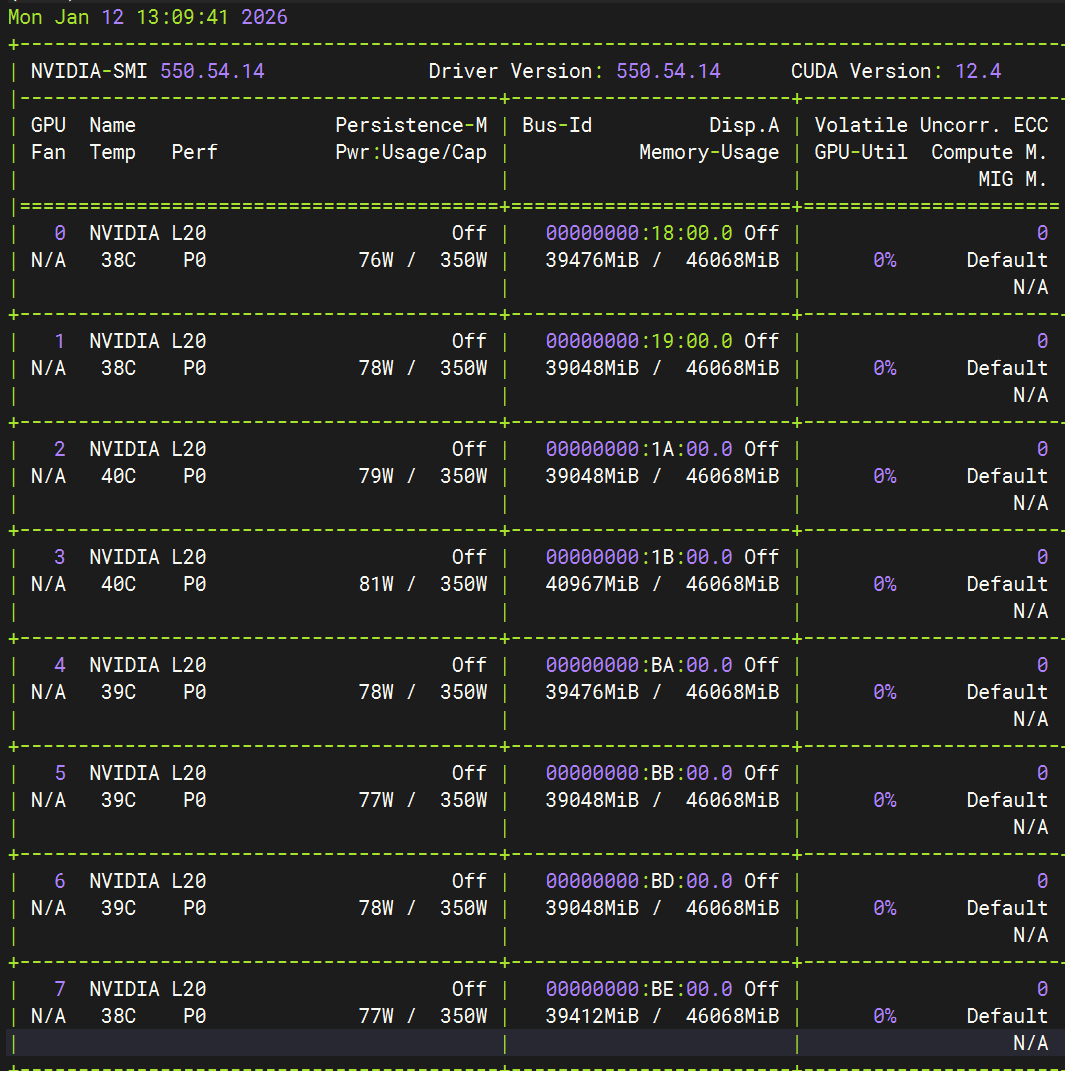
查看GPU占用情况:
nvidia-smi
性能测试方法(需要安装llmperf):
export OPENAI_API_BASE="https://{your-ip}:{your-port}/v1"
python token_benchmark_ray.py \
--model "deepseek-671b-v3" \
--mean-input-tokens 550 \
--stddev-input-tokens 150 \
--mean-output-tokens 150 \
--stddev-output-tokens 10 \
--max-num-completed-requests 10 \
--timeout 600 \
--num-concurrent-requests 1 \
--results-dir "result_outputs" \
--llm-api openai \
--additional-sampling-params '{}'