内容
在单台8卡L20服务器上进行全模态AI系统一体化部署:LLM、VLM、Embedding/Reranker、ASR、Dify与Mineru实战指南。
LLM的显存估算公式

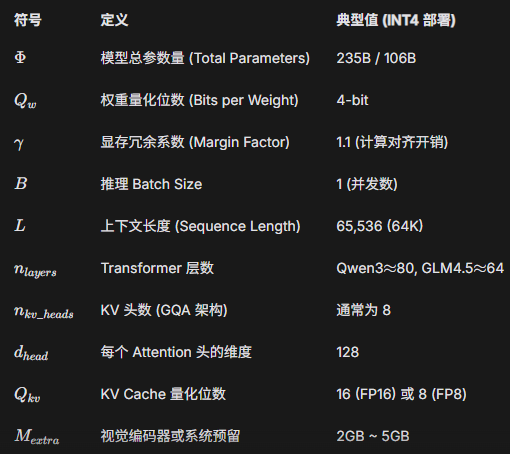
鉴于大语言模型(LLM)的性能与参数规模(B)之间的相关性显著高于量化程度(Quantization),因此在模型选型上优先考虑参数规模更大的模型,最终选用 Qwen3-235B 和 GLM-4.5V-106B的int4版本,以最大化整体性能表现。
Qwen3-235B模型的显存占用估算:
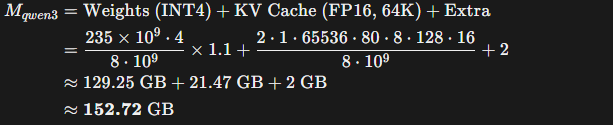
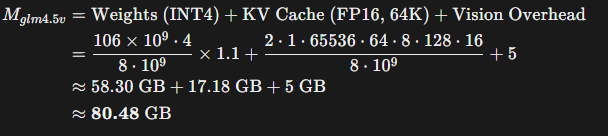
GLM-4.5V-106B的显存占用估算:
模型的下载可通过HuggingFace或Modelscope.
LLM
前置条件:安装 Docker 下载 Vllm 镜像(版本大于v0.11.0)+ 下载 Qwen235B int4量化版本
使用docker compose 方式启动
version: '3'
services:
qwen3-235b-instruct:
image: vllm/vllm-openai:v0.11.0
container_name: qwen3-235b-instruct
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ['0','1','2','3']
volumes:
- /your/path/to/qwen3-235b-instruct-awq:/root/models
ports:
- "10000:8000"
shm_size: '2g'
command: >
--model /root/models
--host 0.0.0.0
--port 8000
--trust-remote-code
--served-model-name LLM
--gpu-memory-utilization 0.75
--enable-auto-tool-choice
--tool-call-parser hermes
--max-model-len 65536
--tensor-parallel-size 4
--api-key your-api-key
VLM
前置条件:安装 Docker 下载 Vllm 镜像(版本大于v0.11.0)+ 下载 GLM-4.5V-106B int4量化版本
使用docker compose 方式启动
version: '3'
services:
glm-4.5v-106b:
image: vllm/vllm-openai:v0.11.0
container_name: glm-4.5v-106b
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ['4', '5', '6', '7']
command: >
--model /root/models
--host 0.0.0.0
--port 8000
--trust-remote-code
--enable-auto-tool-choice
--enable-expert-parallel
--served-model-name VLM
--tool-call-parser glm45
--reasoning-parser glm45
--gpu-memory-utilization 0.45
--max-model-len 42000
--tensor-parallel-size 4
--api-key your-api-key
volumes:
- /your/path/to/glm-4.5v-awq:/root/models
ports:
- "10001:8000"
Embedding/Reranker
前置条件:安装 Docker 下载 Vllm 镜像(版本大于v0.11.0)+ 下载Qwen3-4B-Embedding和Qwen3-4B-Reranker
qwen3-4b-embedding:
image: vllm/vllm-openai:v0.11.0
container_name: qwen3-4b-embedding
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ['4','5','6','7']
volumes:
- /your/path/to/qwen3-4b-embedding:/root/models
ports:
- "10004:8000"
shm_size: '1g'
command: >
--model /root/models
--host 0.0.0.0
--port 8000
--trust-remote-code
--served-model-name EMBEDDING
--gpu-memory-utilization 0.08
--max-model-len 8192
--tensor-parallel-size 4
--api-key your-api-key
qwen3-4b-reranker:
image: vllm/vllm-openai:v0.11.0
container_name: qwen3-4b-reranker
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
device_ids: ['4','5','6','7']
volumes:
- /your/path/to/qwen3-4b-reranker:/root/models
ports:
- "10005:8000"
shm_size: '1g'
command: >
--model /root/models
--host 0.0.0.0
--port 8000
--trust-remote-code
--served-model-name RERANKER
--task score
--gpu-memory-utilization 0.08
--max-model-len 8192
--tensor-parallel-size 4
--api-key your-api-key
Dify
克隆Dify仓库
将环境变量复制,并且强烈建议修改其中nginx代理的端口号:
cd ./docker
--修改以下参数:
EXPOSE_NGINX_PORT=10080
EXPOSE_NGINX_SSL_PORT=10443
cp .env.example .env
然后直接使用docker-compose 启动
ASR
前置条件:搭建conda环境,并下载asr模型:
conda activate your-conda-env
下载:
--语音转文字 speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404
--断句检测 speech_fsmn_vad_zh-cn-16k-common-pytorch
--标点符号检测 punc_ct-transformer_zh-cn-common-vocab272727-pytorch
--说话人分别 speech_campplus_sv_zh-cn_16k-common
然后创建脚本asr_minimal.py:
import argparse
from funasr import AutoModel
def main():
parser = argparse.ArgumentParser()
parser.add_argument("audio", type=str)
args = parser.parse_args()
model = AutoModel(
# ASR 主模型:负责“语音 → 文本”
model="./speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404",
# VAD 模型:语音活动检测
vad_model="./speech_fsmn_vad_zh-cn-16k-common-pytorch",
# 标点模型:自动恢复中文标点
punc_model="./punc_ct-transformer_zh-cn-common-vocab272727-pytorch",
# 说话人模型:区分不同说话人(可选)
spk_model="./speech_campplus_sv_zh-cn_16k-common",
)
result = model.generate(input=args.audio)
# 最小化输出:直接打印识别文本
print("识别结果:")
print(result[0]["text"])
if __name__ == "__main__":
main()
使用案例:
python asr_minimal.py your-example-audio.wav
MinerU
前置条件:下载MinerU v2.5版本镜像
mineru-server:
image: mineru:v2.5
container_name: mineru-server
ports:
- 30000:30000
environment:
MINERU_MODEL_SOURCE: local
ipc: host
entrypoint: mineru-vllm-server
command:
--host 0.0.0.0
--port 30000
--data-parallel-size 2
--gpu-memory-utilization 0.1
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:30000/health || exit 1"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['4','5']
capabilities: [gpu]
mineru-api:
image: mineru:v2.5
container_name: mineru-api
profiles: ["api"]
ports:
- 10018:8000
environment:
MINERU_MODEL_SOURCE: local
ipc: host
entrypoint: mineru-api
command:
--host 0.0.0.0
--port 8000
--data-parallel-size 2
--gpu-memory-utilization 0.1
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['6','7']
capabilities: [gpu]
mineru-gradio:
image: mineru:v2.5
container_name: mineru-gradio
profiles: ["gradio"]
ports:
- 30002:7860
environment:
MINERU_MODEL_SOURCE: local
entrypoint: mineru-gradio
command:
--server-name 0.0.0.0
--server-port 7860
--enable-vllm-engine true
--data-parallel-size 2
--gpu-memory-utilization 0.1
ipc: host
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["6","7"]
capabilities: [gpu]